牛客网经典之webserver项目学习总结记录,其中主要包括了:
使用多线程模型,利用信号量实现线程间加锁;
利用I0复用技术Epoll与线程池实现多线程的Reactor高并发模型;
利用RAII机制实现了数据库连接池,减少数据库连接建立与关闭的开销;
利用正则与状态机解析 HTTP请求报文实现处理静态资源的请求;
基于小根堆实现的定时器,关闭超时的非活动连接;
服务器压力测试;
项目总结
1 总体介绍 1.1 项目需求 实现一个高性能的 Web Server, 就是一个服务器软件(程序)。其主要功能是通过 HTTP 协议与客户端进行通信,来接收,存储,处理来自客户端的 HTTP 请求,并对其请求做出 HTTP 响应,返回给客户端其请求的内容或返回一个 Error 信息。
1.2 项目主要内容
使用多线程模型,利用信号量实现线程间加锁
利用I0复用技术Epoll与线程池实现多线程的Reactor高并发模型
利用RAⅡ机制实现了数据库连接池,减少数据库连接建立与关闭的开销
利用正则与状态机解析 HTTP请求报文实现处理静态资源的请求
基于小根堆实现的定时器,关闭超时的非活动连接
服务器压力测试
2 信号量加锁和多线程模型 由于使用多线程模型,则需要使用到锁,保证同时只有一个线程对文件fd进行操作,通过信号来对线程间进行交互,使用条件量来进一步控制线程。
封装locker.h头文件,创建locker类、条件变量类cond和信号量类sem。
2.1 locker类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class locker {public : locker () { if (pthread_mutex_init (&m_mutex, NULL ) != 0 ) { throw std::exception (); } } ~locker () { pthread_mutex_destroy (&m_mutex); } bool lock () return pthread_mutex_lock (&m_mutex) == 0 ; } bool unlock () return pthread_mutex_unlock (&m_mutex) == 0 ; } pthread_mutex_t *get () { return &m_mutex; } private : pthread_mutex_t m_mutex; };
2.2 条件变量类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class cond {public : cond (){ if (pthread_cond_init (&m_cond, NULL ) != 0 ) { throw std::exception (); } } ~cond () { pthread_cond_destroy (&m_cond); } bool wait (pthread_mutex_t *m_mutex) return pthread_cond_wait (&m_cond, m_mutex) == 0 ; } bool timewait (pthread_mutex_t *m_mutex, struct timespec t) return pthread_cond_timedwait (&m_cond, m_mutex, &t) == 0 ; } bool signal () return pthread_cond_signal (&m_cond) == 0 ; } bool broadcast () return pthread_cond_broadcast (&m_cond) == 0 ; } private : pthread_cond_t m_cond; };
2.3 信号量类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class sem {public : sem () { if ( sem_init ( &m_sem, 0 , 0 ) != 0 ) { throw std::exception (); } } sem (int num) { if ( sem_init ( &m_sem, 0 , num ) != 0 ) { throw std::exception (); } } ~sem () { sem_destroy ( &m_sem ); } bool wait () return sem_wait ( &m_sem ) == 0 ; } bool post () return sem_post ( &m_sem ) == 0 ; } private : sem_t m_sem; };
3 IO复用、Epoll和线程池实现Reactor高并发模型 3.1 IO复用介绍
简单来说就是单线程或单进程同时监测若干个文件描述符是否可以执行IO操作的能力。
3.2 Epoll介绍
在项目中主要运用水平触发监听Epoll,在主函数main中,对事件进行监听EPOLLIN、EPOLLOUT和EPOLLERR等进行检测,并进行相应的操作。
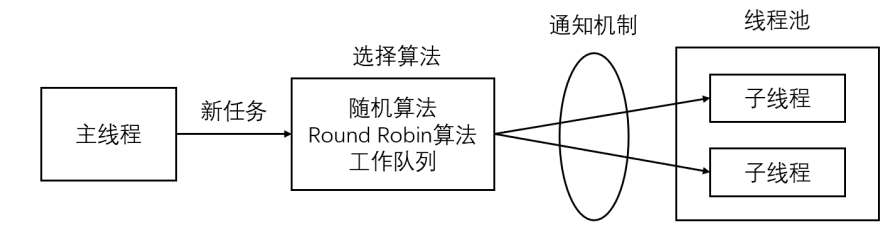
3.3 线程池 线程池是由服务器预先创建的一组子线程。线程池中的所有子线程都运行着相同的代码。当有新的任务到来时,主线程将通过某种方式选择线程池中的某一个子线程来为之服务。相比与动态的创建子线程,选择一个已经存在的子线程的代价显然要小得多。至于主线程选择哪个子线程来为新任务服务,则有多种方式:
主线程使用某种算法来主动选择子线程。最简单、最常用的算法是随机算法和 Round Robin(轮流选取)算法,但更优秀、更智能的算法将使任务在各个工作线程中更均匀地分配,从而减轻服务器的整体压力。
主线程和所有子线程通过一个共享的工作队列来同步,子线程都睡眠在该工作队列上。当有新的任务到来时,主线程将任务添加到工作队列中。这将唤醒正在等待任务的子线程,不过只有一个子线程将获得新任务的接管权,它可以从工作队列中取出任务并执行之,而其他子线程将继续睡眠在工作队列上。
线程池的一般模型为:
线程池中的线程数量最直接的限制因素是CPU的处理器的数量N :如果你的CPU是4-cores的,对于CPU密集型的任务来说,那线程池中的线程数量最好也设置为4(或者+1防止其他因素造成的线程阻塞);对于IO密集型的任务,一般要多于CPU的核数,因为线程间竞争的不是CPU的计算资源而是IO,IO的处理一般较慢,多于cores数的线程将为CPU争取更多的任务,不至在线程处理IO的过程造成CPU空闲导致资源浪费。
空间换时间,浪费服务器的硬件资源,换取运行效率。
池是一组资源的集合,这组资源在服务器启动之初就被完全创建好并初始化,这称为静态资源。
当服务器进入正式运行阶段,开始处理客户请求的时候,如果它需要相关的资源,可以直接从池中获取,无需动态分配。
当服务器处理完一个客户连接后,可以把相关的资源放回池中,无需执行系统调用释放资源。
创建threadpool.h,封装线程池类threadpool,并且使用模版类方便移植。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 template <typename T>class threadpool {public : threadpool (int thread_number = 8 , int max_requests = 10000 ); ~threadpool (); bool append (T* request) private : static void * worker (void * arg) void run () private : int m_thread_number; pthread_t * m_threads; int m_max_requests; std::list< T* > m_workqueue; locker m_queuelocker; sem m_queuestat; bool m_stop; };
构造函数threadpool(int thread_number, int max_requests):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 template < typename T >threadpool< T >::threadpool (int thread_number, int max_requests) : m_thread_number (thread_number), m_max_requests (max_requests), m_stop (false ), m_threads (NULL ) { if ((thread_number <= 0 ) || (max_requests <= 0 ) ) { throw std::exception (); } m_threads = new pthread_t [m_thread_number]; if (!m_threads) { throw std::exception (); } for ( int i = 0 ; i < thread_number; ++i ) { printf ( "create the %dth thread\n" , i); if (pthread_create (m_threads + i, NULL , worker, this ) != 0 ) { delete [] m_threads; throw std::exception (); } if ( pthread_detach ( m_threads[i] ) ) { delete [] m_threads; throw std::exception (); } } }
析构函数:
1 2 3 4 5 6 7 template < typename T >threadpool< T >::~threadpool () { delete [] m_threads; m_stop = true ; }
append函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 template < typename T >bool threadpool< T >::append ( T* request ){ m_queuelocker.lock (); if ( m_workqueue.size () > m_max_requests ) { m_queuelocker.unlock (); return false ; } m_workqueue.push_back (request); m_queuelocker.unlock (); m_queuestat.post (); return true ; }
工作worker函数:
1 2 3 4 5 6 7 8 9 template < typename T >void * threadpool< T >::worker ( void * arg ){ threadpool* pool = ( threadpool* )arg; pool->run (); return pool; }
运行run函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 template < typename T >void threadpool< T >::run () { while (!m_stop) { m_queuestat.wait (); m_queuelocker.lock (); if ( m_workqueue.empty () ) { m_queuelocker.unlock (); continue ; } T* request = m_workqueue.front (); m_workqueue.pop_front (); m_queuelocker.unlock (); if ( !request ) { continue ; } request->process (); } }
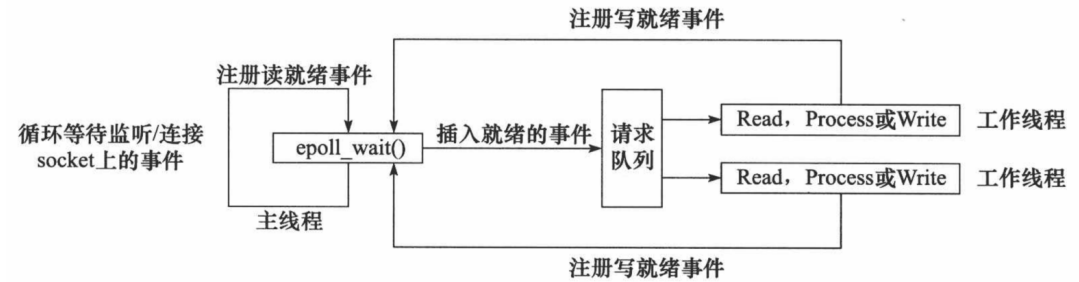
3.4 Reactor模型 服务器程序通常需要处理三类事件:I/O 事件、信号及定时事件。有两种高效的事件处理模式:Reactor和 Proactor,同步 I/O 模型通常用于实现 Reactor 模式,异步 I/O 模型通常用于实现 Proactor 模式。
要求主线程(I/O处理单元)只负责监听文件描述符上是否有事件发生,有的话就立即将该事件通知工作线程(逻辑单元),将 socket 可读可写事件放入请求队列,交给工作线程处理。除此之外,主线程不做任何其他实质性的工作。读写数据,接受新的连接,以及处理客户请求均在工作线程中完成。
主线程往 epoll 内核事件表中注册 socket 上的读就绪事件。
主线程调用 epoll_wait 等待 socket 上有数据可读。
当 socket 上有数据可读时, epoll_wait 通知主线程。主线程则将 socket 可读事件放入请求队列。
睡眠在请求队列上的某个工作线程被唤醒,它从 socket 读取数据,并处理客户请求,然后往 epoll
当主线程调用 epoll_wait 等待 socket 可写。
当 socket 可写时,epoll_wait 通知主线程。主线程将 socket 可写事件放入请求队列。
睡眠在请求队列上的某个工作线程被唤醒,它往 socket 上写入服务器处理客户请求的结果。
Reactor 模式的工作流程:
4 RAⅡ机制 RAII(Resource Acquisition Is Initialization)中文翻译为资源获取即初始化:使用局部对象来管理资源的技术称为资源获取即初始化;这里的资源主要是指操作系统中有限的东西如内存、网络套接字等等,局部对象是指存储在栈的对象,它的生命周期是由操作系统来管理的,无需人工介入;
资源的使用一般经历三个步骤a.获取资源 b.使用资源 c.销毁资源,但是资源的销毁往往是程序员经常忘记的一个环节,所以程序界就想如何在程序员中让资源自动销毁呢
整个RAII过程总结四个步骤:
设计一个类封装资源
在构造函数中初始化
在析构函数中执行销毁操作
使用时声明一个该对象的类
5 核心处理逻辑HTTP_CONN 文件包括http_conn.h和http_conn.cpp。
5.1 初始化操作 在头文件class http_conn 中定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 public : static const int FILENAME_LEN = 200 ; static const int READ_BUFFER_SIZE = 2048 ; static const int WRITE_BUFFER_SIZE = 1024 ; void init (int sockfd, const sockaddr_in& addr) void close_conn () void process () bool read () bool write () private : void init () HTTP_CODE process_read () ; bool process_write ( HTTP_CODE ret ) public : static int m_epollfd; static int m_user_count; private : int m_sockfd; sockaddr_in m_address; char m_read_buf[ READ_BUFFER_SIZE ]; int m_read_idx; int m_checked_idx; int m_start_line; CHECK_STATE m_check_state; METHOD m_method; char m_real_file[ FILENAME_LEN ]; char * m_url; char * m_version; char * m_host; int m_content_length; bool m_linger; char m_write_buf[ WRITE_BUFFER_SIZE ]; int m_write_idx; char * m_file_address; struct stat m_file_stat; struct iovec m_iv[2 ]; int m_iv_count; int bytes_to_send; int bytes_have_send;
其中HTTP_CODE是我们解析HTTP请求的有限状态机
具体函数在http_conn.cpp定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 #include "http_conn.h" int setnonblocking ( int fd ) int old_option = fcntl ( fd, F_GETFL ); int new_option = old_option | O_NONBLOCK; fcntl ( fd, F_SETFL, new_option ); return old_option; } void addfd ( int epollfd, int fd, bool one_shot ) epoll_event event; event.data.fd = fd; event.events = EPOLLIN | EPOLLRDHUP; if (one_shot) { event.events |= EPOLLONESHOT; } epoll_ctl (epollfd, EPOLL_CTL_ADD, fd, &event); setnonblocking (fd); } void http_conn::init (int sockfd, const sockaddr_in& addr) m_sockfd = sockfd; m_address = addr; int reuse = 1 ; setsockopt ( m_sockfd, SOL_SOCKET, SO_REUSEADDR, &reuse, sizeof ( reuse ) ); addfd ( m_epollfd, sockfd, true ); m_user_count++; init (); } void http_conn::init () bytes_to_send = 0 ; bytes_have_send = 0 ; m_check_state = CHECK_STATE_REQUESTLINE; m_linger = false ; m_method = GET; m_url = 0 ; m_version = 0 ; m_content_length = 0 ; m_host = 0 ; m_start_line = 0 ; m_checked_idx = 0 ; m_read_idx = 0 ; m_write_idx = 0 ; bzero (m_read_buf, READ_BUFFER_SIZE); bzero (m_write_buf, READ_BUFFER_SIZE); bzero (m_real_file, FILENAME_LEN); } void removefd ( int epollfd, int fd ) epoll_ctl ( epollfd, EPOLL_CTL_DEL, fd, 0 ); close (fd); } void http_conn::close_conn () if (m_sockfd != -1 ) { removefd (m_epollfd, m_sockfd); m_sockfd = -1 ; m_user_count--; } } void modfd (int epollfd, int fd, int ev) epoll_event event; event.data.fd = fd; event.events = ev | EPOLLET | EPOLLONESHOT | EPOLLRDHUP; epoll_ctl ( epollfd, EPOLL_CTL_MOD, fd, &event ); } int http_conn::m_user_count = 0 ;int http_conn::m_epollfd = -1 ;void http_conn::process () HTTP_CODE read_ret = process_read (); if ( read_ret == NO_REQUEST ) { modfd ( m_epollfd, m_sockfd, EPOLLIN ); return ; } bool write_ret = process_write ( read_ret ); if ( !write_ret ) { close_conn (); } modfd ( m_epollfd, m_sockfd, EPOLLOUT); }
5.2 解析HTTP请求报文(正则表达式和有限状态机) 有限状态机:有限状态机是一种用来进行对象行为建模的工具,其作用主要是描述对象在它的生命周期内所经历的状态序列,以及如何响应来自外界的各种事件,比如TCP就是一个典型的有限状态机。
本项目定义四种状态
METHOD:为HTTP请求方法,项目中仅支持GET
CHECK_STATE:解析客户端请求时,主状态机的状态
CHECK_STATE_REQUESTLINE:当前正在分析请求行
CHECK_STATE_HEADER:当前正在分析头部字段
CHECK_STATE_CONTENT:当前正在解析请求体
HTTP_CODE:服务器处理HTTP请求的可能结果,报文解析的结果
NO_REQUEST : 请求不完整,需要继续读取客户数据
GET_REQUEST : 表示获得了一个完成的客户请求
BAD_REQUEST : 表示客户请求语法错误
NO_RESOURCE : 表示服务器没有资源
FORBIDDEN_REQUEST : 表示客户对资源没有足够的访问权限
FILE_REQUEST : 文件请求,获取文件成功
INTERNAL_ERROR : 表示服务器内部错误
CLOSED_CONNECTION : 表示客户端已经关闭连接了
LINE_STATUS:从状态机的三种可能状态,即行的读取状态
LINE_OK: 读取到一个完整的行
LINE_BAD: 行出错
LINE_OPEN: 行数据尚且不完整
头文件中添加相应函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 enum METHOD {GET = 0 , POST, HEAD, PUT, DELETE, TRACE, OPTIONS, CONNECT};enum CHECK_STATE { CHECK_STATE_REQUESTLINE = 0 , CHECK_STATE_HEADER, CHECK_STATE_CONTENT };enum HTTP_CODE { NO_REQUEST, GET_REQUEST, BAD_REQUEST, NO_RESOURCE, FORBIDDEN_REQUEST, FILE_REQUEST, INTERNAL_ERROR, CLOSED_CONNECTION };enum LINE_STATUS { LINE_OK = 0 , LINE_BAD, LINE_OPEN };HTTP_CODE parse_request_line ( char * text ) ;HTTP_CODE parse_headers ( char * text ) ;HTTP_CODE parse_content ( char * text ) ;HTTP_CODE do_request () ;char * get_line () return m_read_buf + m_start_line; }LINE_STATUS parse_line () ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 bool http_conn::read () if ( m_read_idx >= READ_BUFFER_SIZE ) { return false ; } int bytes_read = 0 ; while (true ) { bytes_read = recv (m_sockfd, m_read_buf + m_read_idx, READ_BUFFER_SIZE - m_read_idx, 0 ); if (bytes_read == -1 ) { if ( errno == EAGAIN || errno == EWOULDBLOCK ) { break ; } return false ; } else if (bytes_read == 0 ) { return false ; } m_read_idx += bytes_read; } return true ; } http_conn::LINE_STATUS http_conn::parse_line () { char temp; for ( ; m_checked_idx < m_read_idx; ++m_checked_idx ) { temp = m_read_buf[ m_checked_idx ]; if ( temp == '\r' ) { if ( ( m_checked_idx + 1 ) == m_read_idx ) { return LINE_OPEN; } else if ( m_read_buf[ m_checked_idx + 1 ] == '\n' ) { m_read_buf[ m_checked_idx++ ] = '\0' ; m_read_buf[ m_checked_idx++ ] = '\0' ; return LINE_OK; } return LINE_BAD; } else if ( temp == '\n' ) { if ( ( m_checked_idx > 1 ) && ( m_read_buf[ m_checked_idx - 1 ] == '\r' ) ) { m_read_buf[ m_checked_idx-1 ] = '\0' ; m_read_buf[ m_checked_idx++ ] = '\0' ; return LINE_OK; } return LINE_BAD; } } return LINE_OPEN; } http_conn::HTTP_CODE http_conn::parse_request_line (char * text) { m_url = strpbrk (text, " \t" ); if (! m_url) { return BAD_REQUEST; } *m_url++ = '\0' ; char * method = text; if ( strcasecmp (method, "GET" ) == 0 ) { m_method = GET; } else { return BAD_REQUEST; } m_version = strpbrk ( m_url, " \t" ); if (!m_version) { return BAD_REQUEST; } *m_version++ = '\0' ; if (strcasecmp ( m_version, "HTTP/1.1" ) != 0 ) { return BAD_REQUEST; } if (strncasecmp (m_url, "http://" , 7 ) == 0 ) { m_url += 7 ; m_url = strchr ( m_url, '/' ); } if ( !m_url || m_url[0 ] != '/' ) { return BAD_REQUEST; } m_check_state = CHECK_STATE_HEADER; return NO_REQUEST; } http_conn::HTTP_CODE http_conn::parse_headers (char * text) { if ( text[0 ] == '\0' ) { if ( m_content_length != 0 ) { m_check_state = CHECK_STATE_CONTENT; return NO_REQUEST; } return GET_REQUEST; } else if ( strncasecmp ( text, "Connection:" , 11 ) == 0 ) { text += 11 ; text += strspn ( text, " \t" ); if ( strcasecmp ( text, "keep-alive" ) == 0 ) { m_linger = true ; } } else if ( strncasecmp ( text, "Content-Length:" , 15 ) == 0 ) { text += 15 ; text += strspn ( text, " \t" ); m_content_length = atol (text); } else if ( strncasecmp ( text, "Host:" , 5 ) == 0 ) { text += 5 ; text += strspn ( text, " \t" ); m_host = text; } else { printf ( "oop! unknow header %s\n" , text ); } return NO_REQUEST; } http_conn::HTTP_CODE http_conn::parse_content ( char * text ) { if ( m_read_idx >= ( m_content_length + m_checked_idx ) ) { text[ m_content_length ] = '\0' ; return GET_REQUEST; } return NO_REQUEST; } http_conn::HTTP_CODE http_conn::process_read () { LINE_STATUS line_status = LINE_OK; HTTP_CODE ret = NO_REQUEST; char * text = 0 ; while (((m_check_state == CHECK_STATE_CONTENT) && (line_status == LINE_OK)) || ((line_status = parse_line ()) == LINE_OK)) { text = get_line (); m_start_line = m_checked_idx; printf ( "got 1 http line: %s\n" , text ); switch ( m_check_state ) { case CHECK_STATE_REQUESTLINE: { ret = parse_request_line ( text ); if ( ret == BAD_REQUEST ) { return BAD_REQUEST; } break ; } case CHECK_STATE_HEADER: { ret = parse_headers ( text ); if ( ret == BAD_REQUEST ) { return BAD_REQUEST; } else if ( ret == GET_REQUEST ) { return do_request (); } break ; } case CHECK_STATE_CONTENT: { ret = parse_content ( text ); if ( ret == GET_REQUEST ) { return do_request (); } line_status = LINE_OPEN; break ; } default : { return INTERNAL_ERROR; } } } return NO_REQUEST; }
5.3 写响应 头文件中添加相应函数:
1 2 3 4 5 6 7 8 9 10 void unmap () bool add_response ( const char * format, ... ) bool add_content ( const char * content ) bool add_content_type () bool add_status_line ( int status, const char * title ) bool add_headers ( int content_length ) bool add_content_length ( int content_length ) bool add_linger () bool add_blank_line ()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 const char * ok_200_title = "OK" ;const char * error_400_title = "Bad Request" ;const char * error_400_form = "Your request has bad syntax or is inherently impossible to satisfy.\n" ;const char * error_403_title = "Forbidden" ;const char * error_403_form = "You do not have permission to get file from this server.\n" ;const char * error_404_title = "Not Found" ;const char * error_404_form = "The requested file was not found on this server.\n" ;const char * error_500_title = "Internal Error" ;const char * error_500_form = "There was an unusual problem serving the requested file.\n" ;const char * doc_root = "/home/mobbu/myWebserver/resources" ;http_conn::HTTP_CODE http_conn::do_request () strcpy ( m_real_file, doc_root ); int len = strlen ( doc_root ); strncpy ( m_real_file + len, m_url, FILENAME_LEN - len - 1 ); if ( stat ( m_real_file, &m_file_stat ) < 0 ) { return NO_RESOURCE; } if ( ! ( m_file_stat.st_mode & S_IROTH ) ) { return FORBIDDEN_REQUEST; } if ( S_ISDIR ( m_file_stat.st_mode ) ) { return BAD_REQUEST; } int fd = open ( m_real_file, O_RDONLY ); m_file_address = ( char * )mmap ( 0 , m_file_stat.st_size, PROT_READ, MAP_PRIVATE, fd, 0 ); close ( fd ); return FILE_REQUEST; } void http_conn::unmap () if ( m_file_address ) { munmap ( m_file_address, m_file_stat.st_size ); m_file_address = 0 ; } } bool http_conn::write () int temp = 0 ; if ( bytes_to_send == 0 ) { modfd ( m_epollfd, m_sockfd, EPOLLIN ); init (); return true ; } while (1 ) { temp = writev (m_sockfd, m_iv, m_iv_count); if ( temp <= -1 ) { if ( errno == EAGAIN ) { modfd ( m_epollfd, m_sockfd, EPOLLOUT ); return true ; } unmap (); return false ; } bytes_have_send += temp; bytes_to_send -= temp; if (bytes_have_send >= m_iv[0 ].iov_len) { m_iv[0 ].iov_len = 0 ; m_iv[1 ].iov_base = m_file_address + (bytes_have_send - m_write_idx); m_iv[1 ].iov_len = bytes_to_send; } else { m_iv[0 ].iov_base = m_write_buf + bytes_have_send; m_iv[0 ].iov_len = m_iv[0 ].iov_len - temp; } if (bytes_to_send <= 0 ) { unmap (); modfd (m_epollfd, m_sockfd, EPOLLIN); if (m_linger) { init (); return true ; } else { return false ; } } } } bool http_conn::add_response ( const char * format, ... ) if ( m_write_idx >= WRITE_BUFFER_SIZE ) { return false ; } va_list arg_list; va_start ( arg_list, format ); int len = vsnprintf ( m_write_buf + m_write_idx, WRITE_BUFFER_SIZE - 1 - m_write_idx, format, arg_list ); if ( len >= ( WRITE_BUFFER_SIZE - 1 - m_write_idx ) ) { return false ; } m_write_idx += len; va_end ( arg_list ); return true ; } bool http_conn::add_status_line ( int status, const char * title ) return add_response ( "%s %d %s\r\n" , "HTTP/1.1" , status, title ); } bool http_conn::add_headers (int content_len) add_content_length (content_len); add_content_type (); add_linger (); add_blank_line (); } bool http_conn::add_content_length (int content_len) return add_response ( "Content-Length: %d\r\n" , content_len ); } bool http_conn::add_linger () return add_response ( "Connection: %s\r\n" , ( m_linger == true ) ? "keep-alive" : "close" ); } bool http_conn::add_blank_line () return add_response ( "%s" , "\r\n" ); } bool http_conn::add_content ( const char * content ) return add_response ( "%s" , content ); } bool http_conn::add_content_type () return add_response ("Content-Type:%s\r\n" , "text/html" ); } bool http_conn::process_write (HTTP_CODE ret) switch (ret) { case INTERNAL_ERROR: add_status_line ( 500 , error_500_title ); add_headers ( strlen ( error_500_form ) ); if ( ! add_content ( error_500_form ) ) { return false ; } break ; case BAD_REQUEST: add_status_line ( 400 , error_400_title ); add_headers ( strlen ( error_400_form ) ); if ( ! add_content ( error_400_form ) ) { return false ; } break ; case NO_RESOURCE: add_status_line ( 404 , error_404_title ); add_headers ( strlen ( error_404_form ) ); if ( ! add_content ( error_404_form ) ) { return false ; } break ; case FORBIDDEN_REQUEST: add_status_line ( 403 , error_403_title ); add_headers (strlen ( error_403_form)); if ( ! add_content ( error_403_form ) ) { return false ; } break ; case FILE_REQUEST: add_status_line (200 , ok_200_title ); add_headers (m_file_stat.st_size); m_iv[ 0 ].iov_base = m_write_buf; m_iv[ 0 ].iov_len = m_write_idx; m_iv[ 1 ].iov_base = m_file_address; m_iv[ 1 ].iov_len = m_file_stat.st_size; m_iv_count = 2 ; bytes_to_send = m_write_idx + m_file_stat.st_size; return true ; default : return false ; } m_iv[ 0 ].iov_base = m_write_buf; m_iv[ 0 ].iov_len = m_write_idx; m_iv_count = 1 ; bytes_to_send = m_write_idx; return true ; }
5.4 关闭非活跃连接 在程序内部添加定时处理任务,并添加到监听的文件描述,定时比如设置5s,超过5s没有操作的事件就删除,否则会有将文件操作符用完的情况。
1 2 3 4 5 6 7 8 9 void timer_handler () timer_lst.tick (); alarm (TIMESLOT); }
6 主函数 包含main函数,文件main.cpp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <stdio.h> #include <unistd.h> #include <errno.h> #include <string.h> #include <fcntl.h> #include <stdlib.h> #include <sys/epoll.h> #include "locker.h" #include "threadpool.h" #include "http_conn.h" #define MAX_FD 65536 #define MAX_EVENT_NUMBER 10000 extern void addfd ( int epollfd, int fd, bool one_shot ) extern void removefd ( int epollfd, int fd ) void addsig (int sig, void ( handler )(int )) struct sigaction sa; memset ( &sa, '\0' , sizeof ( sa ) ); sa.sa_handler = handler; sigfillset ( &sa.sa_mask ); assert ( sigaction ( sig, &sa, NULL ) != -1 ); } int main ( int argc, char * argv[] ) if ( argc <= 1 ) { printf ( "usage: %s port_number\n" , basename (argv[0 ])); return 1 ; } int port = atoi ( argv[1 ] ); addsig ( SIGPIPE, SIG_IGN ); threadpool< http_conn >* pool = NULL ; try { pool = new threadpool<http_conn>; } catch ( ... ) { return 1 ; } http_conn* users = new http_conn[ MAX_FD ]; int listenfd = socket ( PF_INET, SOCK_STREAM, 0 ); int ret = 0 ; struct sockaddr_in address; address.sin_addr.s_addr = INADDR_ANY; address.sin_family = AF_INET; address.sin_port = htons ( port ); int reuse = 1 ; setsockopt ( listenfd, SOL_SOCKET, SO_REUSEADDR, &reuse, sizeof ( reuse ) ); ret = bind ( listenfd, ( struct sockaddr* )&address, sizeof ( address ) ); ret = listen ( listenfd, 5 ); epoll_event events[ MAX_EVENT_NUMBER ]; int epollfd = epoll_create ( 5 ); addfd ( epollfd, listenfd, false ); http_conn::m_epollfd = epollfd; while (true ) { int number = epoll_wait ( epollfd, events, MAX_EVENT_NUMBER, -1 ); if ( ( number < 0 ) && ( errno != EINTR ) ) { printf ( "epoll failure\n" ); break ; } for ( int i = 0 ; i < number; i++ ) { int sockfd = events[i].data.fd; if ( sockfd == listenfd ) { struct sockaddr_in client_address; socklen_t client_addrlength = sizeof ( client_address ); int connfd = accept ( listenfd, ( struct sockaddr* )&client_address, &client_addrlength ); if ( connfd < 0 ) { printf ( "errno is: %d\n" , errno ); continue ; } if ( http_conn::m_user_count >= MAX_FD ) { close (connfd); continue ; } users[connfd].init ( connfd, client_address); } else if ( events[i].events & ( EPOLLRDHUP | EPOLLHUP | EPOLLERR ) ) { users[sockfd].close_conn (); } else if (events[i].events & EPOLLIN) { if (users[sockfd].read ()) { pool->append (users + sockfd); } else { users[sockfd].close_conn (); } } else if ( events[i].events & EPOLLOUT ) { if ( !users[sockfd].write () ) { users[sockfd].close_conn (); } } } } close ( epollfd ); close ( listenfd ); delete [] users; delete pool; return 0 ; }
7 压力测试 Webbench 是 Linux 上一款知名的、优秀的 web 性能压力测试工具。它是由Lionbridge公司开发。
测试处在相同硬件上,不同服务的性能以及不同硬件上同一个服务的运行状况。
展示服务器的两项内容:每秒钟响应请求数和每秒钟传输数据量。
基本原理:Webbench 首先 fork 出多个子进程,每个子进程都循环做 web 访问测试。子进程把访问的结果通过pipe 告诉父进程,父进程做最终的统计结果。
实例:
1 webbench -c 1000 -t 30 http://192.168.110.129:10000/index.html
参数:
8 总结 项目详细的总流程:Reactor模式
8.1 一个完整的工作流程
一个客户端发起连接
检测到连接,初始化新接收的连接,比如设置端口复用、状态设置、将epollfd设置为ontshot,保证只有一个线程操作等。
如果检测到错误或者客户端断开连接,则断开连接
检测到读事件,进行数据的读取,并且将对应的文件描述符添加到线程池中
线程池对添加的任务进行运行操作,process_read()分次解析报文,当解析完毕时,process_write()会生成响应报文,生成完毕后会将m_epollfd修改检测EPOLLOUT写事件
检测到写事件,对生成的响应报文进行分部分发送到客户端socket地址
写完毕后,关闭连接
8.2 不同部分的总结 8.2.1主函数中:
首先判断进程号是否小于1,小于1则报错pool,在堆区创建 users=new http_conn[ MAX_FD ];while循环
8.2.2 http_conn::read()函数 8.2.3 http_conn::write()函数 8.2.4 threadpool::worker工作线程逻辑: 流程如下:
threadpool::work()->threadpool::run()->http_conn::process()->http_conn::process_read()->http_conn::process_write()